
L'event loop NodeJS et l'asynchrone
NodeJS démystifie la programmation asynchrone et rend les applications temps réel triviales à programmer. Mais comment est conçu ce "langage"? Explications sur le fonctionnement d'un serveur pas comme les autres.
Fonctionnement d'un serveur web classique
Pour comprendre comment marche Nodejs, il faut d'abord expliquer comment fonctionne un serveur web classique.
En général un serveur web utilise plusieurs processus pour répondre aux requêtes. Dès qu'une connexion arrive, elle est assignée à un processus qui va la traiter. Avec cette architecture, le calcul est simple : 10 requêtes simultanées = 10 processus concurrents.
Cette approche à l'avantage d'être simple, utilisée depuis longtemps et maitrisée car chaque processus est indépendant et leurs exécutions ne s'entrecroisent pas! La programmation est elle aussi simple, car on n'a pas à gérer la concurrence. Par contre elle cache en réalité un désavantage de taille: Chaque processus, qu'il soit utilisé ou non, consommera toujours de la mémoire et du CPU. C'est dommage pour une application qui passera 50% du temps à attendre le transfert de données depuis ou vers internet !
NodeJS et l'asynchrone simple processus
Nodejs adopte une approche totalement différente. Ce serveur est uniquement monothreadé. C'est-à-dire qu'il n'y a qu'un seul processus qui tourne, quel que soit le nombre de clients ou de requêtes en cours.
Les exécutions de code vont s'entrelacer et node va mettre à profit les temps d'attente des diverses connexions (réception des demandes, appels a la base de données, autres connexions distantes) pour traiter plusieurs demandes en simultané.
Par exemple, voici une application qui appelle une base de données avant de renvoyer une réponse :
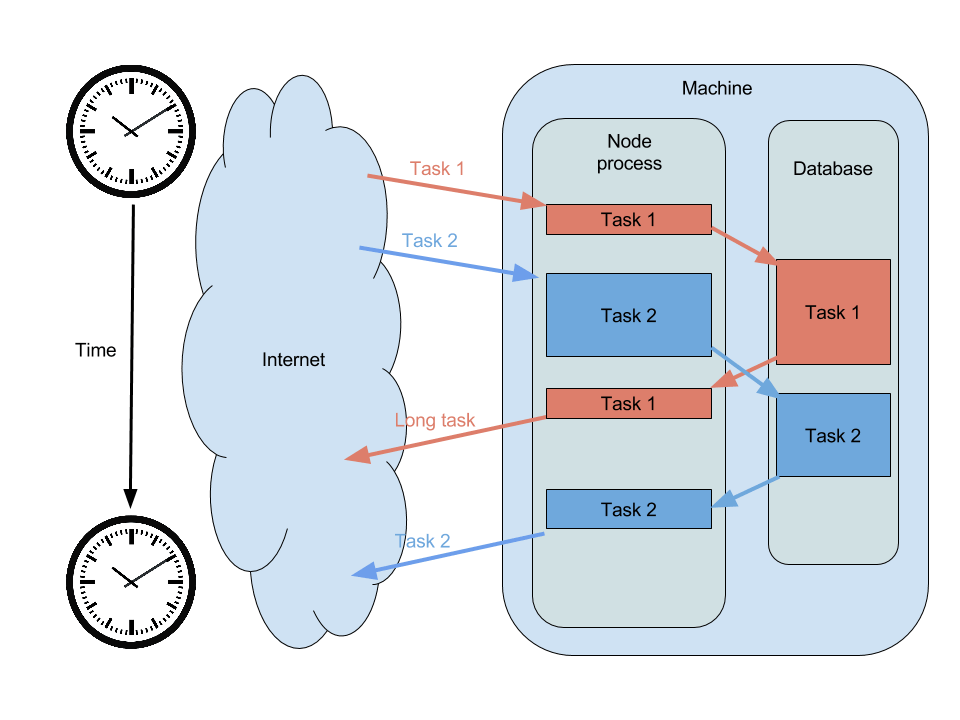
On voit sur cette illustration que les deux requêtes sont entrelacées. Chacune profite du temps laissé par l'autre pour s'exécuter. On crée ainsi l'illusion qu'elles sont exécutées en simultané, tout en utilisant un seul et unique processus !
Les piéges de cette approche
Dans le cas où notre application passe du temps à attendre via des appels asynchrone (on parle d'io bound), cette architecture fonctionne parfaitement !
Maintenant, si on bloque l'event loop de NodeJS en fesant des calculs longs par exemple, notre application est alors CPU Bound. Il faut garder à l'esprit que node ne peut faire qu'une chose à la fois. Les autres opérations asynchrones ne pourront pas débuter tant que cette opération bloquante ne sera pas terminée.
L'illustration suivante montre la même application, mais qui va cette fois faire des calculs pendant 10 secondes avant de répondre. Comme le système d'évènements de node est bloqué, la seconde requête doit attendre avant d'avoir une chance de s'exécuter.
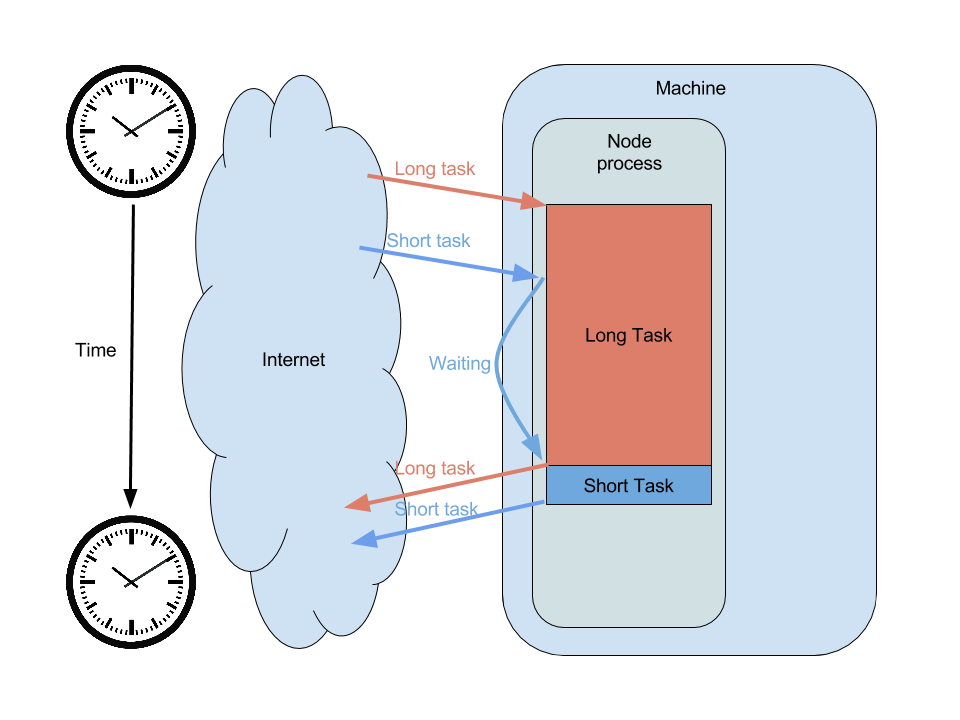
Sur cette illustration, on voit bien que la première requête bloque le processus de node et retarde l'exécution de la seconde. Et voila on vient tout juste de faire tomber nous-même notre propre service !
Savoir quand l'utiliser
Comme pour chaque techno, il faut savoir quand l'utiliser et quand s'en détacher. Pour le cas de node, l'asynchrone le rend performant si notre application passe plus de temps à gerer des entrées/sorties qu'a faire des calculs. Ce sera donc l'outil idéal pour une application utilisant des websockets ou une Api de consultation.
Inversement, si notre application est vouée a faire des calculs lourds frequement, il faudra utiliser une autre technologie en plus ou a coté de nodejs. On pourra par exemple déporter ces calculs vers un autre processus via une librairie C. Ou alors découper notre application en micro services, permettant de mélanger et d'utiliser chaque technologie au meilleur endroit possible !

